From Symbolic Logic to Statistical Learning: The Fascinating Evolution of AI and Its Unexpected Convergence
As a computer engineer who had the privilege of working extensively with Semantic Web technologies between 2011 and 2013 — a period that resulted in three published papers on the subject — I’ve witnessed firsthand how AI concepts migrated and evolved across different domains. Looking back at that era and observing today’s AI landscape dominated by large language models like GPT-4, Claude, and Gemini, I’m struck by how the fundamental tensions and synergies between different AI approaches have shaped our current technological moment.
The story of Artificial Intelligence isn’t just a linear progression of increasingly sophisticated algorithms. It’s a fascinating tale of two competing philosophies that emerged simultaneously, developed in parallel for decades, and are now converging in ways that early pioneers could hardly have imagined. This convergence offers profound lessons about technological evolution and provides crucial context for understanding where AI might be heading next.
The Great Divide: Two Visions of Intelligence
The roots of today’s AI revolution trace back to the legendary Dartmouth Conference of 1956, where John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon laid the conceptual foundation for artificial intelligence. However, even from these early days, two fundamentally different approaches emerged, each based on distinct assumptions about the nature of intelligence itself.
The Symbolic Approach: Intelligence as Logic
The symbolic AI tradition, championed by pioneers like Allen Newell and Herbert Simon, was built on what they called the Physical Symbol System Hypothesis. This approach viewed intelligence as the manipulation of discrete symbols according to logical rules—essentially, thinking as computation over meaningful representations.
This philosophy gave birth to some of AI’s early spectacular successes: expert systems like MYCIN for medical diagnosis and DENDRAL for chemical analysis could solve complex problems and, crucially, explain their reasoning in human-understandable terms. These systems could handle sophisticated logical relationships and incorporate expert knowledge directly through carefully crafted rule bases. Also the PROLOG programming language was created based on the ideas inspired by the symbolic AI movement.
However, symbolic AI encountered fundamental limitations that would plague it for decades:
- The Brittleness Problem: Systems failed catastrophically when encountering situations outside their narrowly defined domains
- The Knowledge Acquisition Bottleneck: Encoding human expertise into rule-based systems proved incredibly labor-intensive and often incomplete
- The Frame Problem: Difficulty in handling the vast contextual knowledge required for real-world reasoning
The Connectionist Revolution: Intelligence as Pattern Recognition
Simultaneously, the connectionist approach drew inspiration from neuroscience and psychology. Frank Rosenblatt’s perceptron in 1957 embodied this alternative vision: intelligence should emerge from the interactions of simple, neuron-like processing units rather than explicit symbol manipulation.
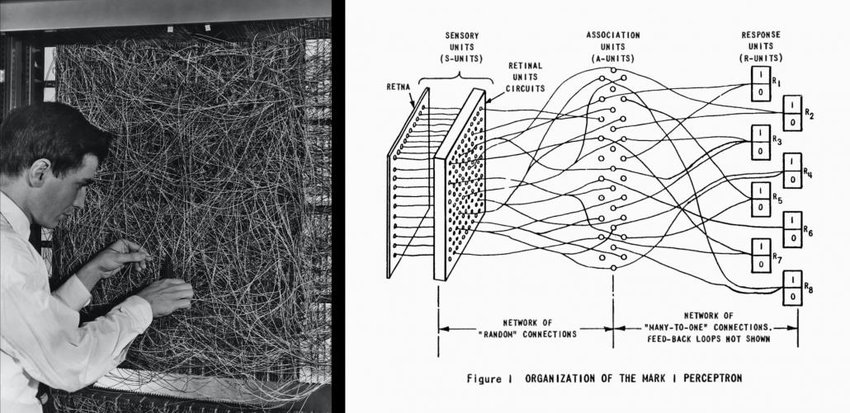
This approach faced its own early challenges. Minsky and Papert’s influential 1969 critique demonstrated fundamental limitations of single-layer networks, leading to what became known as the first “AI winter” and causing many researchers to abandon neural networks entirely.
The field remained relatively dormant until the 1980s, when the backpropagation algorithm—developed by David Rumelhart, Geoffrey Hinton, and Ronald Williams—showed how to train multi-layer neural networks effectively. Even then, connectionist approaches remained largely academic curiosities for another two decades.
The Semantic Web: Symbolic AI’s Web-Scale Renaissance
During my own work with Semantic Web technologies in the early 2010s, I was essentially witnessing symbolic AI principles finding new expression at web scale. Tim Berners-Lee’s vision of the Semantic Web was fundamentally rooted in the same knowledge representation traditions that had driven symbolic AI since the 1950s.
The Resource Description Framework (RDF) with its subject-predicate-object triple format was essentially a web-scale implementation of the semantic networks that researchers like Ross Quillian had developed in the 1960s. When you create an RDF statement like <Company:Apple> <hasFounder> <Person:SteveJobs>, you’re using the same kind of symbolic assertion that early AI systems employed for knowledge representation.
Web Ontology Language (OWL) made this connection even more explicit. Built on description logics — an evolution of the frame-based systems that Minsky and others had developed - OWL provided sophisticated mechanisms for defining class hierarchies, property restrictions, and logical relationships. OWL reasoners like Pelican and HermiT were essentially expert system inference engines applied to web-scale data.
What was remarkable about this period was how the Semantic Web both scaled up and democratized symbolic AI techniques. Early expert systems had been carefully crafted by knowledge engineers working with domain experts in closed environments. The Semantic Web vision aimed to apply these same principles in a distributed, open environment where anyone could contribute structured knowledge.
However, the Semantic Web also encountered many of the same fundamental challenges that had limited traditional symbolic AI: the knowledge acquisition bottleneck persisted (creating high-quality ontologies remained difficult), systems remained brittle when encountering unexpected data structures, and the grounding problem—connecting symbolic representations to real-world meaning—remained as challenging as ever.
The Statistical Revolution: When Data Became King
While I was working with RDF triples and OWL ontologies, a quiet revolution was building in the machine learning community. The period from 2010 to 2012 was, in retrospect, the calm before an extraordinary storm. Machine learning existed primarily in academic circles, with industry applications limited to specific niches like recommendation systems and search ranking. Deep learning was considered a fringe approach, with most practitioners relying on support vector machines, random forests, and other traditional statistical methods.
Then came the breakthrough that changed everything.
2012: The AlexNet Moment
September 2012 marked a pivotal moment in AI history when Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton published “ImageNet Classification with Deep Convolutional Neural Networks.” Their AlexNet architecture achieved a 15.3% top-5 error rate on the ImageNet dataset, dramatically outperforming the previous best result of 26.2%.
This wasn’t just an incremental improvement—it was a paradigm shift that couldn’t be ignored. AlexNet demonstrated several crucial innovations:
- GPU acceleration for training deep networks at unprecedented scale
- ReLU activations that solved vanishing gradient problems
- Dropout regularization that prevented overfitting
- Data augmentation techniques that effectively expanded training datasets
The impact was immediate and profound. Computer vision researchers worldwide had to reconsider fundamental assumptions about what was possible with neural networks.
2017: The Transformer Revolution
The next seismic shift came with the publication of “Attention Is All You Need” by Ashish Vaswani and colleagues at Google in June 2017. The Transformer architecture eliminated the need for recurrent connections in neural networks, replacing them with attention mechanisms that could be massively parallelized.
This architectural innovation was elegant in its simplicity but revolutionary in its implications. Transformers enabled:
- Massive parallelization during training, making it feasible to train much larger models
- Long-range dependencies in sequences without the vanishing gradient problems that plagued RNNs
- Transfer learning at unprecedented scale through pre-training and fine-tuning
The Transformer became the foundation for every major language model that followed: BERT, GPT, T5, and eventually the large language models that dominate today’s AI landscape.
The Scale Era: 2020 and Beyond
May 2020 brought another watershed moment with OpenAI’s release of GPT-3, featuring 175 billion parameters. For the first time, a neural network demonstrated something approaching general-purpose intelligence, capable of few-shot learning, code generation, creative writing, and complex reasoning tasks.
The release of ChatGPT in November 2022 finally brought AI capabilities to mainstream public consciousness, achieving 100 million users in just two months and triggering a global AI adoption race that continues today.
The Unexpected Convergence: Neural Meets Symbolic
What makes this historical moment particularly fascinating is how the apparent opposition between symbolic and statistical approaches is resolving into a collaborative synthesis. Modern AI systems increasingly combine the strengths of both paradigms rather than relying exclusively on either.
Large Language Models as Hybrid Systems
Today’s large language models like GPT-4, Claude, and Gemini represent a remarkable synthesis of symbolic and statistical approaches. While trained through statistical optimization on vast text corpora, these models perform something analogous to symbolic reasoning through their attention mechanisms and transformer architecture.
When Claude engages in step-by-step logical reasoning or maintains consistent knowledge representations across a conversation, it’s exhibiting behaviors that symbolic AI systems were explicitly designed to support, but achieving them through learned statistical patterns rather than explicit logical rules.
Knowledge Graphs Meet Neural Networks
The Semantic Web infrastructure I worked with in the early 2010s has found new purpose as the symbolic component in hybrid AI systems. Modern applications combine:
- Knowledge graph embeddings (TransE, ComplEx, DistMult) that represent symbolic knowledge in continuous vector spaces accessible to neural networks
- Graph neural networks that can operate on structured knowledge while leveraging statistical pattern recognition
- Neuro-symbolic reasoning systems that use symbolic methods for precise logical inference while employing neural networks for pattern recognition and uncertainty handling
Companies like Google, Facebook, and Amazon now use knowledge graphs not as standalone Semantic Web applications, but as structured knowledge sources that enhance neural language models and recommendation systems.
Differentiable Programming and Neural Modules
Emerging approaches like differentiable programming allow symbolic reasoning to be embedded within neural architectures. Neural Module Networks can decompose complex reasoning tasks into modular, interpretable components while still learning end-to-end through gradient descent.
These systems represent a mature engineering approach to the symbolic-statistical integration challenge, using symbolic structures to ensure consistency and enable precise reasoning while employing machine learning for perception, pattern recognition, and handling uncertainty.
Lessons from History: Understanding Technological Evolution
The evolution from symbolic AI through the Semantic Web to modern neural-symbolic hybrid systems offers several important insights about technological progress:
Fundamental Concepts Persist Across Paradigm Shifts
The symbolic AI techniques developed in the 1970s and 1980s didn’t disappear when machine learning became dominant; they found new expression in web technologies and are now being integrated into neural systems. Knowledge representation, logical inference, and structured reasoning remain crucial components of intelligent systems, even when implemented through different technological approaches.
Scale and Synthesis Trump Purity
The most powerful systems combine multiple approaches rather than adhering to a single paradigm. Modern AI succeeds not by choosing between symbolic reasoning and statistical learning, but by finding engineering solutions that leverage the strengths of both.
Infrastructure Matters
The Semantic Web’s standards (RDF, OWL, SPARQL) and knowledge graphs now serve as ready-made infrastructure for deploying hybrid AI systems. Sometimes the most important contribution of a technological approach isn’t its immediate applications but the foundational infrastructure it creates for future innovations.
The Modern Machine Learning Renaissance: Key Milestones (2011-2024)
The Pre-Explosion Era (2010-2012)
The Quiet Period Before the Storm
-
2010-2012: Machine learning exists primarily in academic circles. Industry applications are limited to specific niches like recommendation systems (Netflix, Amazon) and search ranking. Deep learning is considered a fringe approach, with most practitioners using SVMs, random forests, and traditional statistical methods.
-
2011: IBM’s Watson defeats human champions in Jeopardy! - but this is seen as a specialized symbolic AI achievement rather than a machine learning breakthrough.
-
2012 (Early): The field is still dominated by hand-crafted features and traditional methods. Computer vision relies heavily on SIFT, HOG, and other engineered descriptors.
The Ignition: Computer Vision Revolution (2012-2014)
2012 - The AlexNet Breakthrough
- September 2012: Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton publish “ImageNet Classification with Deep Convolutional Neural Networks” (AlexNet)
- Impact: Achieves 15.3% top-5 error rate on ImageNet, dramatically outperforming previous best result of 26.2%
- Significance: First clear demonstration that deep learning could outperform traditional computer vision methods at scale
- Technical Innovation: Utilized GPUs for training, ReLU activations, dropout regularization, and data augmentation
2013 - The Acceleration Begins
- 2013: Google acquires DeepMind for $400 million - first major tech acquisition focused on deep learning
- 2013: Word2Vec published by Tomas Mikolov at Google, revolutionizing natural language processing with dense word embeddings
- 2013: ZFNet wins ImageNet with 11.7% error rate, confirming deep learning’s dominance in computer vision
2014 - Foundation Models Emerge
- 2014: Ian Goodfellow introduces Generative Adversarial Networks (GANs) - revolutionizes generative modeling
- 2014: VGGNet and GoogleNet (Inception) achieve human-level performance on ImageNet classification
- 2014: Facebook’s DeepFace achieves 97.35% accuracy on face verification, approaching human performance
- 2014: Sequence-to-sequence learning with neural networks (Sutskever et al.) - foundational for modern NLP
The Platform Wars (2015-2016)
2015 - Infrastructure and Accessibility
- November 2015: Google releases TensorFlow as open source - democratizes deep learning development
- 2015: Microsoft releases CNTK, Facebook releases Torch (later PyTorch in 2017)
- 2015: ResNet introduces skip connections, enabling training of very deep networks (152 layers)
- 2015: AlphaGo defeats Fan Hui (professional Go player) - DeepMind combines deep learning with tree search
2016 - Mainstream Breakthrough
- March 2016: AlphaGo defeats Lee Sedol 4-1 in historic match watched by 200 million people
- Impact: Mainstream media recognizes AI’s potential; massive increase in public interest and investment
- 2016: ResNet achieves 3.57% error on ImageNet - surpasses human-level performance
The Language Revolution (2017-2019)
2017 - The Transformer Revolution
- June 2017: “Attention Is All You Need” paper introduces the Transformer architecture (Vaswani et al., Google)
- Technical Breakthrough: Eliminates need for recurrent connections, enables massive parallelization
- Impact: Becomes foundation for all subsequent large language models
- 2017: PyTorch 1.0 released by Facebook - provides more intuitive dynamic computation graphs
2018 - The Pre-trained Language Model Era Begins
- June 2018: OpenAI releases GPT-1 (117M parameters) - demonstrates unsupervised pre-training potential
- October 2018: Google releases BERT - bidirectional encoder representations from transformers
- Impact: BERT achieves state-of-the-art on 11 NLP tasks, showing power of pre-training + fine-tuning paradigm
- 2018: Google introduces TPUs (Tensor Processing Units) - specialized hardware for AI workloads
2019 - Scaling Laws Emerge
- February 2019: OpenAI releases GPT-2 (1.5B parameters) - initially withheld for safety concerns
- Significance: Demonstrates emergent capabilities from scale; generates coherent long-form text
- 2019: NVIDIA releases RTX series with Tensor cores - accelerates AI development in consumer market
- 2019: AlphaStar defeats professional StarCraft II players - complex real-time strategy game
The Scale Revolution (2020-2022)
2020 - The GPT-3 Moment
- May 2020: OpenAI releases GPT-3 (175B parameters) via API
- Cultural Impact: First AI system to capture widespread public imagination since AlphaGo
- Capabilities: Few-shot learning, code generation, creative writing - demonstrates general-purpose intelligence
- Business Impact: Spawns entire ecosystem of AI-powered applications
2020-2021 - Computer Vision Advances
- 2020: DALL-E demonstrates text-to-image generation
- 2021: CLIP (Contrastive Language-Image Pre-training) enables zero-shot image classification
- 2021: GitHub Copilot launches (powered by OpenAI Codex) - AI-assisted programming goes mainstream
2021-2022 - Multimodal and Scientific AI
- 2021: AlphaFold 2 solves protein folding problem - demonstrates AI’s potential for scientific discovery
- 2022: ChatGPT launches (November) - first truly mainstream AI application
- Impact: 100 million users in 2 months; triggers global AI adoption race
The Generative AI Explosion (2022-2024)
2022 - The Creative Revolution
- April 2022: DALL-E 2 released - high-quality text-to-image generation
- August 2022: Stable Diffusion released as open source - democratizes image generation
- September 2022: Midjourney gains popularity - AI art becomes mainstream
- November 2022: ChatGPT launch triggers global AI race
2023 - The Commercial Breakthrough
- March 2023: GPT-4 released - multimodal capabilities, significant performance improvements
- March 2023: Microsoft integrates GPT-4 into Bing - search wars reignite around AI
- May 2023: Google releases Bard, PaLM 2 - tech giants compete directly on conversational AI
- 2023: Anthropic releases Claude, focusing on AI safety and constitutional AI
2024 - The Reasoning Frontier
- 2024: OpenAI releases GPT-4o (omni-modal) - real-time voice, vision, and text interaction
- 2024: Anthropic releases Claude 3 family - Opus, Sonnet, Haiku with different capability/efficiency trade-offs
- 2024: Google releases Gemini Ultra - first model to exceed human expert performance on MMLU benchmark
- 2024: AI agents and code generation reach production quality - GitHub Copilot, Cursor, Claude Code
Key Enabling Factors
Hardware Evolution
- 2012: NVIDIA’s CUDA ecosystem matures for GPU computing
- 2016: Google develops TPUs specifically for neural network training
- 2020s: Specialized AI chips from Google, Tesla, Cerebras, and others
Data Availability
- 2009: ImageNet dataset created - provides large-scale labeled data for computer vision
- 2010s: Internet-scale text data becomes available for language model training
- 2020s: Multimodal datasets enable vision-language models
Algorithmic Innovations
- 2015: Residual connections solve vanishing gradient problem
- 2017: Attention mechanism eliminates sequence processing bottlenecks
- 2020: Scaling laws discovered - performance predictably improves with compute, data, and parameters
Economic Factors
- 2010s: Cloud computing reduces barrier to entry for ML experimentation
- 2015+: Venture capital floods into AI startups
- 2020+: Enterprise adoption accelerates due to remote work and digital transformation
The Current Landscape (2024-Present)
Today’s AI landscape is characterized by:
- Foundation Models: Large pre-trained models adapted for specific tasks
- Multimodal AI: Systems that process text, images, audio, and video together
- AI Agents: Systems that can plan, reason, and take actions autonomously
- Democratization: Powerful AI capabilities available through APIs and open source
- Specialization: Task-specific models optimized for efficiency and performance
Looking Forward: The Continuing Evolution
As we stand at this remarkable moment in AI history, several trends seem clear:
Multimodal Integration: Future systems will seamlessly combine text, images, audio, and structured data, requiring both the pattern recognition capabilities of neural networks and the precise relationship modeling of symbolic systems.
Explainable AI: As AI systems become more powerful and widely deployed, the interpretability advantages of symbolic reasoning become increasingly valuable, driving continued research into neural-symbolic integration.
Scientific Discovery: Applications like AlphaFold (protein folding) and AlphaGeometry (mathematical theorem proving) demonstrate how hybrid systems can tackle problems requiring both pattern recognition and logical reasoning.
The story of AI’s evolution from symbolic logic to statistical learning—and their ongoing convergence—reminds us that technological progress rarely follows straight lines. Instead, it involves cycles of divergence and synthesis, with ideas finding new expression across different domains and eras.
As someone who worked extensively with Semantic Web technologies during their peak and now witnesses their integration into modern AI systems, I’m struck by how foundational concepts persist and evolve rather than simply being replaced. The symbolic-statistical synthesis we’re seeing today isn’t just a technical achievement: it’s a vindication of the insight that intelligence itself likely requires both logical reasoning and statistical learning, working in concert rather than in opposition.
The next chapter of this story is still being written, but the historical trajectory suggests that the most powerful AI systems will continue to find innovative ways to combine the precision of symbolic reasoning with the adaptability of statistical learning. For engineers working at the cutting edge of AI, understanding this historical context isn’t just intellectually satisfying—it’s essential for anticipating where the field is heading and building systems that can leverage the full spectrum of intelligence techniques.